Lightweight RoBERTa Sequence Classification Fine-Tuning with LORA using the Hugging Face PEFT library.

Fine-tuning large language models (LLMs) like RoBERTa can produce remarkable results when adapting them to specific tasks.
Unfortunately, it can also be slow and computationally expensive.
In a previous article, we explored Fine-tuning RoBERTa for Topic Classification with Hugging Face Transformers and Datasets Library.
This article will explore how to make that fine-tuning process more efficient using LORA (Low-Rank Adaptation) by leveraging the 🤗PEFT (Parameter-Efficient Fine-Tuning) library.
Pros:
- Parameter Efficiency: Drastically reduces the number of trainable parameters when adapting large language models, saving training time, storage, and computational costs.
- Can Combine with Other Methods: LoRA can be used with other model adaptation techniques, such as prefix-tuning, to enhance the model further.
Cons:
- Adaptation: Introduces an additional layer of hyperparameter tuning (specific to LORA’s rank, alpha, etc.).
- Performance: in some cases, performance is not as optimal as with fully fine-tuned models.
Let’s get our hands dirty 😁
!pip install transformers datasets evaluate accelerate peftPreprocessing
import torch
from transformers import RobertaModel, RobertaTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, DataCollatorWithPadding
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
peft_model_name = 'roberta-base-peft'
modified_base = 'roberta-base-modified'
base_model = 'roberta-base'
dataset = load_dataset('ag_news')
tokenizer = RobertaTokenizer.from_pretrained(base_model)
def preprocess(examples):
tokenized = tokenizer(examples['text'], truncation=True, padding=True)
return tokenized
tokenized_dataset = dataset.map(preprocess, batched=True, remove_columns=["text"])
train_dataset=tokenized_dataset['train']
eval_dataset=tokenized_dataset['test'].shard(num_shards=2, index=0)
test_dataset=tokenized_dataset['test'].shard(num_shards=2, index=1)
# Extract the number of classess and their names
num_labels = dataset['train'].features['label'].num_classes
class_names = dataset["train"].features["label"].names
print(f"number of labels: {num_labels}")
print(f"the labels: {class_names}")
# Create an id2label mapping
# We will need this for our classifier.
id2label = {i: label for i, label in enumerate(class_names)}
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="pt")Training
Let’s Train two models, one using LORA and the other with full fine-tuning. Note the LORA setup's training times and the number of trained parameters!
# use the same Training args for all models
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='steps',
learning_rate=5e-5,
num_train_epochs=1,
per_device_train_batch_size=16,
)def get_trainer(model):
return Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)Perform full fine-tuning
full_finetuning_trainer = get_trainer(
AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label),
)
full_finetuning_trainer.train()
PEFT LORA Training
All model params: 125,537,288
LORA model trainable params: 888,580
We only have to train ~0.70% of the parameters with LORA!
model = AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label)
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
peft_model = get_peft_model(model, peft_config)
print('PEFT Model')
peft_model.print_trainable_parameters()
peft_lora_finetuning_trainer = get_trainer(peft_model)
peft_lora_finetuning_trainer.train()
peft_lora_finetuning_trainer.evaluate()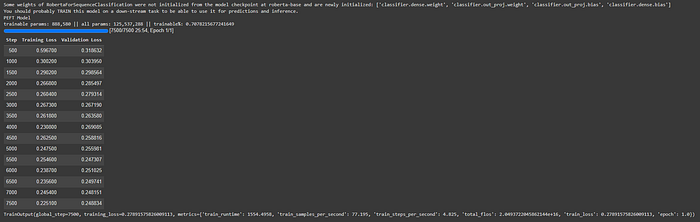
Save the PEFT model
# Save
tokenizer.save_pretrained(modified_base)
peft_model.save_pretrained(peft_model_name)Test the PEFT Model
It's time to have some fun putting our model to work!
from peft import AutoPeftModelForSequenceClassification
from transformers import AutoTokenizer
# LOAD the Saved PEFT model
inference_model = AutoPeftModelForSequenceClassification.from_pretrained(peft_model_name, id2label=id2label)
tokenizer = AutoTokenizer.from_pretrained(modified_base)
def classify(text):
inputs = tokenizer(text, truncation=True, padding=True, return_tensors="pt")
output = inference_model(**inputs)
prediction = output.logits.argmax(dim=-1).item()
print(f'\n Class: {prediction}, Label: {id2label[prediction]}, Text: {text}')
# return id2label[prediction]classify( "Kederis proclaims innocence Olympic champion Kostas Kederis today left hospital ahead of his date with IOC inquisitors claiming his ...")
classify( "Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\band of ultra-cynics, are seeing green again.")
Evaluate the Models
We will need a baseline to measure the improvement of our Training process; let’s compare the trained models with an untrained one.
Take a Look at:
- The performance of trained models against the untrained one
- The PEFT Model performance vs the fully fine-tuned one
from torch.utils.data import DataLoader
import evaluate
from tqdm import tqdm
metric = evaluate.load('accuracy')
def evaluate_model(inference_model, dataset):
eval_dataloader = DataLoader(dataset.rename_column("label", "labels"), batch_size=8, collate_fn=data_collator)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
inference_model.to(device)
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric)# Evaluate the non fine-tuned model
evaluate_model(AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label), test_dataset)
# Evaluate the PEFT fine-tuned model
evaluate_model(inference_model, test_dataset)
# Evaluate the Fully fine-tuned model
evaluate_model(full_finetuning_trainer.model, test_dataset)
Congratulations
You have adapted and evaluated a RoBERTa model with LORA for text classification using Hugging Face 🤗 PEFT, transformers, and datasets libraries!
Happy 🤖 learning 😀!
